|
Пример 1: Оценка теста вне пределов выборки
Оценка оптимизированной системы на данных, взятых вне пределов выборки и ни разу не использованных при оптимизации, аналогична оценке неоптимизированной системы. В обоих случаях проводится один тест без подстройки параметров. В табл. 4-1 показано применение статистики для оценки неоптимизированной системы. Там приведены результаты проверки на данных вне пределов выборки совместно с рядом статистических показателей. Помните, что в этом тесте использованы «свежие
данные», которые не применялись как основа для настройки параметров системы.
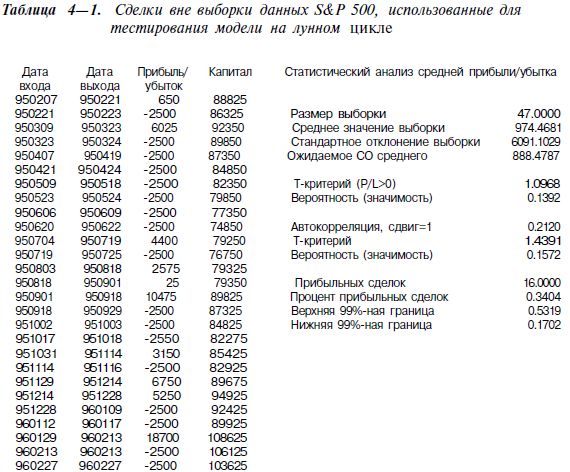
Параметры торговой модели уже были определены. Образец данных для оценки вне пределов выборки охватывает период с 1.01.1995 г. по 1.01.1997 г.; модель тестировалась на этих данных и совершала смоделированные сделки. Было проведено 47 сделок. Этот набор сделок можно считать выборкой сделок, т. е. частью популяции смоделированных сделок, которые система совершила бы по данным правилам в прошлом или будущем. Здесь возникает вопрос по поводу оценки показателя средней
прибыли в сделке — могло ли данное значение быть достигнуто за счет чистой случайности? Чтобы найти ответ, потребуется статистическая оценка системы.
Чтобы начать оценку системы, для начала нужно рассчитать среднее в выборке для n сделок. Среднее здесь будет просто суммой прибылей/убытков, поделенной на n (в данном случае 47). Среднее составило $974,47 за сделку. Стандартное отклонение (изменчивость показателей прибылей/убытков) рассчитывается после этого вычитанием среднего из каждого результата, что дает 47 (n) отклонений. Каждое из значений отклонения возводится в квадрат, все квадраты складываются, сумма квадратов делится на n-1 (в данном случае 46), квадратный корень от результата и будет стандартным отклонением выборки. На основе стандартного отклонения выборки вычисляется ожидаемое стандартное отклонение прибыли в сделке: стандартное отклонение (в данном случае $6091,10) делится на квадратный корень из n. В нашем случае ожидаемое стандартное отклонение составляет $888,48.
Чтобы определить вероятность случайного происхождения наблюдаемой прибыли, проводится простая проверка по критерию Стьюдента. Поскольку прибыльность выборки сравнивается с нулевой прибыльностью, из среднего, вычисленного выше, вычитается ноль, и результат делится на стандартное отклонение выборки для получения значения критерия t, в данном случае — 1,0968. В конце концов оценивается вероятность получения столь большого t по чистой случайности. Для этого рассчитывается функция распределения t для данных показателей с количеством степеней свободы, равным n-1 (или 46).
Программа работы с таблицами Microsoft Excel имеет функцию вычисления вероятностей на основе t-распределения. В сборнике «Numerical Recipes in С» приведены неполные бета-функции, при помощи которых очень легко рассчитывать вероятности, основанные на различных критериях распределения, включая критерий Стьюдента. Функция распределения Стьюдента дает показатели вероятности случайного происхождения результатов системы. Поскольку в данном случае этот показатель был
мал, вряд ли причиной эффективности системы была подгонка под случайные характеристики выборки. Чем меньше этот показатель, тем меньше вероятность того, что эффективность системы обусловлена случаем. В данном случае показатель был равен 0,1392, т. е. при испытании на независимых данных неэффективная система показала бы столь же высокую, как и в тесте, прибыль только в 14% случаев.
Хотя проверка по критерию Стьюдента в этом случае рассчитывалась для прибылей/убытков, она могла быть с равным успехом применена, например, к выборке дневных прибылей. Дневные прибыли именно так использовались в тестах, описанных в последующих главах. Фактически, соотношение риска/прибыли, выраженное в процентах годовых, упоминаемое во многих таблицах и примерах представляет собой t-статистику дневных прибылей.
Кроме того, оценивался доверительный интервал вероятности выигрышной сделки. К примеру, из 47 сделок было 16 выигрышей, т. е. процент прибыльных сделок был равен 0,3404. При помощи особой обратной функции биноминального распределения мы рассчитали верхний и нижний 99%-ные пределы. Вероятность того, что процент прибыльных сделок системы в целом составит от 0,1702 до 0,5319 составляет 99%. В Excel для вычисления доверительных интервалов можно использовать функцию
CRITBINOM.
Различные статистические показатели и вероятности, описанные выше, должны предоставить разработчику системы важную информацию о поведении торговой модели в случае, если соответствуют реальности предположения о нормальном распределении и независимости данных в выборке. Впрочем, чаще всего заключения, основанные на проверке по критерию Стьюдента и других статистических показателях, нарушаются; рыночные данные заметно отклоняются от нормального распределения, и сделки оказываются зависимыми друг от друга. Кроме того, выборка данных может быть непредставительной. Означает ли это, что все вышеописанное не имеет смысла? Рассмотрим примеры.
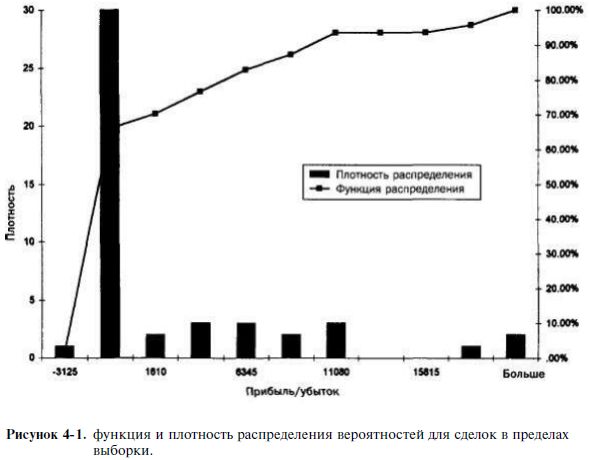
Что, если распределение не соответствует нормальному? При проведении проверки по критерию Стьюдента исходят из предположения, что данные соответствуют нормальному распределению. В реальности распределение показателей прибылей и убытков торговой системы таким не бывает, особенно при наличии защитных остановок и целевых прибылей, как показано на рис. 4-1. Дело в том, что прибыль выше, чем целевая, возникает редко. Фактически большинство прибыльных сделок будут иметь прибыль, близкую к целевой. С другой стороны, кое-какие сделки
закроются с убытком, соответствующим уровню защитной остановки, а между ними будут разбросаны другие сделки, с прибылью, зависящей от методики выхода. Следовательно, это будет совсем непохоже на колоколообразную кривую, которая описывает нормальное распределение. Это составляет нарушение правил, лежащих в основе проверки по критерию Стьюдента. Впрочем, в данном случае спасает так называемая центральная предельная теорема: с ростом числа точек данных в выборке распределение стремится к нормальному. Если размер выборки составит 10, то
ошибки будут небольшими; если же их будет 20-30, ошибки будут иметь исчезающе малое значение для статистических заключений. Следовательно, многие виды статистического анализа можно с уверенностью применять при адекватном размере выборки, например при n=47 и выше, не опасаясь за достоверность заключений.
Что, если существует серийная зависимость? Более серьезным нарушением, способным сделать неправомочным вышеописанное применение проверки по критерию Стьюдента, является серийная зависимость — случай, когда данные в выборке не являются независимыми друг от друга. Сделки совершаются в виде временного ряда. Последовательность сделок, совершенных в течение некоторого периода времени, нельзя назвать случайной выборкой — подлинно случайная выборка состояла бы,
например, из 100 сделок, выбранных случайным образом из всей популяции данных — от начала рынка (например, 1983 г. для S&P 500) до отдаленного будущего. Такая выборка не только была бы защищена от серийной зависимости, но и являлась бы более представительной для популяции. Однако при разработке торговых систем выборка сделок обычно производится на ограниченном временном отрезке; следовательно, может наблюдаться корреляция каждой сделки с соседними, что сделает данные зависимыми.
Практический эффект этого явления состоит в уменьшении размеров выборки. Если между данными существует серийная зависимость, то, делая статистические выводы, следует считать, что выборка в два или в четыре раза меньше реального количества точек данных. Вдобавок определить достоверным образом степень зависимости данных невозможно, можно только сделать грубую оценку — например, рассчитав серийную
корреляцию точки данных с предшествующей и предыдущей точками. Рассчитывается корреляция прибыли/убытка сделки i и прибыли/убытка сделок i+1 и i-1. В данном случае серийная корреляция составила 0,2120. Это немного, но предпочтительным было бы меньшее значение. Можно также рассчитать связанный t-критерий для статистической значимости значения корреляции. В данном случае выясняется, что если бы в популяции действительно не было серьезной зависимости, то такой
уровень корреляции наблюдался бы только в 16% тестов.
Серийная зависимость — серьезная проблема. Если она высока, то для борьбы с ней надо считать выборку меньшей, чем она есть на самом деле. Другой вариант — выбрать случайным образом данные для тестирования из различных участков за длительный период времени. Это также повысит представительность выборки в отношении всей популяции.
Что, если изменится рынок? При разработке торговых систем возможно нарушение третьего положения t-критерия, и его невозможно предугадать или компенсировать. Причина этого нарушения в том, что популяция, из которой взят образец данных для тестирования или разработки, может отличаться от популяции, данные из которой будут использоваться в будущих сделках. Рынок может подвергаться структурным или иным изменениям. Как говорилось, популяция данных S&P 500 до 1983 г. принципиально отличается от последующих данных, когда началась торговля опционами и фьючерсами. Подобные события могут разрушить любой метод оценки системы. Как бы ни проводилось тестирование, при изменении рынка до начала реальной торговли окажется, что система разрабатывалась и тестировалась на одном рынке, а работать будет на другом. Естественно, модель разваливается на части. Даже самая лучшая модель будет уничтожена изменением рынка.
Тем не менее большинство рынков постоянно меняются. Несмотря на этот суровый факт, использование статистики в оценке системы остается принципиально важным, поскольку если рынок не изменится вскоре после начала работы системы или же изменения рынка недостаточны, чтобы оказать глубокое влияние, то статистически возможно произвести достаточно достоверную оценку ожидаемых вероятностей и прибылей системы.
Пример 2: Оценка тестов на данных в пределах выборки
Каким образом можно оценивать систему, которая подвергалась подгонке параметров (т. е. оптимизации) по некоторой выборке данных? Трейдеры часто оптимизируют системы для улучшения результатов. В данном аспекте применение статистики особенно важно, поскольку позволяет анализировать результаты, компенсируя этим большое количество тестовых прогонов во время оптимизации. В табл. 4-2 приведены показатели прибыли/убытка и различные статистические показатели для тестов в пределах выборки (т. е. на данных, использовавшихся для оптимизации системы). Система подвергалась оптимизации на данных за период с
1.01.1990г. по 1.02.1995г.
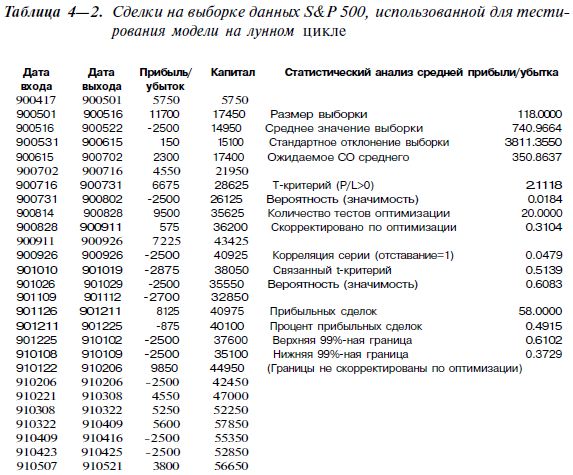
Большая часть статистики в табл. 4-2 идентична показателями табл. 4-1 из примера 1. Добавлены два дополнительных показателя — «Количество тестов оптимизации» и «Скорректировано по оптимизации». Первый показатель — просто количество различных комбинаций параметров, т. е. число испытаний системы по выборке данных с различными параметрами. Поскольку первый параметр системы на лунном цикле, L1, принимал значения от 1 до 20 с шагом в 1, было проведено 20 тестов и соответственно получено 20 значений t-критерия.
Количество тестов, использованных для коррекции вероятности (значимости) по лучшему показателю t-критерия, определяется следующим образом: от 1 отнимается статистическая значимость лучшего теста, результат возводится в степень m (где m — число прогонок тестов). Затем этот результат вычитается из единицы. Это показывает вероятность обнаружения в m тестах (в данном случае m=20) по крайней мере одного значения t-критерия, как минимум не уступающего действительно обнаруженному в данном решении. Некорректированная вероятность случайного происхождения результатов составляет менее 2% — весьма впечатляющий показатель. После коррекции по множественным тестам (оптимизации) картина в корне меняется. Результаты с такой прибыльностью системы могли быть достигнуты чисто случайно в 31% случаев! Впрочем, все не так плохо. Настройка была крайне консервативной и исходила из полной независимости тестов друг от друга. На самом же деле между тестами будет идти значительная серийная корреляция, поскольку в большинстве традиционных систем небольшие изменения параметров вызывают небольшие изменения результатов. Это в точности напоминает серийную зависимость в выборках данных: эффективный размер снижается, если снижается эффективное количество проведенных тестов. Поскольку многие из тестов коррелируют друг с другом, 20 проведенных
соответствуют 5-10 «реальным» независимым тестам. Учитывая серийную зависимость между тестами, вероятность с поправкой на оптимизацию составит около 0,15, а не 0,3104. Поскольку природа и точная величина серийной зависимости тестов неизвестны, менее консервативное заключение об оптимизации не может быть рассчитано напрямую, а только может быть примерно оценено.
В некоторых случаях, например в моделях множественной регрессии, существуют точные математические формулы для расчета статистических параметров с учетом процесса подгонки (оптимизации), что делает излишними поправки на оптимизацию.
Трактовка статистических показателей
В примере 1 представлен тест с проверкой системы, в примере 2 — оптимизация на данных из выборки. При обсуждении результатов мы возвращаемся к естественному порядку проведения тестов, т. е. сначала оптимизация, а потом проверка.
Результаты оптимизации. В табл. 4-2 показаны результаты анализа
данных из выборки. За 5 лет периода оптимизации система провела 118 сделок (n=118), средняя сделка дала прибыль в $740,97, и сделки были весьма различными: стандартное отклонение выборки составило около $3811. Таким образом, во многих сделках убытки составляли тысячи долларов, в других такого же масштаба достигали прибыли. Степень прибыльности легко оценить по столбцу «Прибыль/Убыток», в котором встречается немало убытков в $2500 (на этом уровне активировалась защитная остановка) и значительное количество прибылей, многие более $5000, а
некоторые даже более $10000. Ожидаемое стандартное отклонение средней прибыли в сделке показывает, что если бы такие расчеты многократно проводились на схожих выборках, то среднее колебалось бы в пределах десяти процентов, и многие выборки показывали бы среднюю прибыльность в размере $740±350.
Т-критерий для наилучшего решения составил 2,1118 при статистической значимости 0,0184. Это весьма впечатляющий результат. Если бы тест проводился только один раз (без оптимизации), то вероятность случайно достичь такого значения была бы около 2%, что позволяет заключить, что система с большой вероятностью находит «скрытую неэффективность» рынка и имеет шанс на успех в реальной торговле. Впрочем, не забывайте: исследовались лучшие 20 наборов параметров. Если скорректировать статистическую значимость, то значение составит около 0,31, что вовсе не так хорошо — эффективность вполне может оказаться случайной. Следовательно, система имеет некоторые шансы на выживание в реальной торговле, однако в ее провале не будет ничего удивительного.
Серийная корреляция между сделками составляла всего 0,0479 при значимости 0,6083 — в данном контексте немного. Эти показатели говорят, что значительной серийной корреляции между сделками не наблюдалось, и вышеприведенный статистический анализ, скорее всего, справедлив.
За время проведения теста было 58 прибыльных сделок, т. е. доля прибыльных сделок составила около 49%. Верхняя граница 99%-ного доверительного интервала количества прибыльных сделок составила около 61%, а нижняя — около 37%. Это означает, что доля прибыльных сделок в популяции данных с вероятностью 99% попала бы в интервал от 37 до 61%. Фактически коррекция по оптимизации должна была бы расширить доверительный интервал; но мы этого не делали, поскольку не особенно
интересовались показателем доли прибыльных сделок.
Результаты проверки. В табл. 4-1 содержатся данные и статистические
заключения по тестированию модели на данных вне выборки. Поскольку все параметры уже определены при оптимизации и проводился всего один тест, мы не рассматривали ни оптимизацию, ни ее последствия. За период с 1.01.1995г. по 1.01.1997г. система привела 47 сделок, средняя сделка дала прибыль в $974, что выше, чем в выборке, использованной для оптимизации! Видимо, эффективность системы сохранилась.
Стандартное отклонение выборки составило более $6000, почти вдвое больше, чем в пределах выборки, по которой проводилась оптимизация. Следовательно, стандартное отклонение средней прибыли в сделке было около $890, что составляет немалую ошибку. С учетом небольшого размера выборки это приводит к снижению значения t-критерия по сравнению с полученным при оптимизации и к меньшей статистической значимости — около 14%. Эти результаты не слишком плохи, но и не слишком хороши: вероятность нахождения «скрытой неэффективности» рынка составляет более 80%. Но при этом серийная корреляция в тесте была значительно выше (ее вероятность составила 0,1572). Это означает, что такой серийной корреляции чисто случайно можно достичь лишь в 16% случаев, даже если никакой реальной корреляции в данных нет. Следовательно, и t-критерий прибыли/убытка, скорее всего, переоценил статистическую значимость до некоторой степени (вероятно, на 20-30%). Если размер выборки был бы меньше, то значение t составило бы около 0,18
вместо полученного 0,1392. Доверительный интервал для процента прибыльных сделок в популяции находился в пределах от 17 до приблизительно 53%.
В общем, оценка показывает, что система, вероятно, сможет работать в будущем, но без особой уверенности в успехе. Учитывая, что в одном тесте вероятность случайности прибылей составила 31%, в другом, независимом, — 14% (с коррекцией на оптимизацию 18%), шанс того, что средняя сделка будет выгодной и система в будущем сможет работать, остается неплохим.
Далее
Вернуться к оглавлению
|

